
LLM-powered trading agents represent a fundamentally different workload than traditional MetaTrader Expert Advisors. They demand persistent Python processes, gigabytes of RAM for agent frameworks and memory stores, and reliable outbound API connections to both brokers and LLM providers. The infrastructure requirements have almost nothing in common with the MetaTrader VPS configurations covered in the rest of this site.
The good news: infrastructure costs start as low as roughly $4/month for a cloud-API-only agent on a Linux VPS, making experimentation genuinely accessible. A trader can have a LangChain agent connected to a broker API and calling GPT-4o for analysis running on a Hetzner instance that costs less than a single standard lot commission.
The bad news: no independently verified, long-term track record exists for any LLM-based trading agent generating consistent profits in live markets. The StockBench academic benchmark found LLM agents struggle to consistently outperform simple baselines. In a live trading competition, only 2 of 6 tested LLMs beat buy-and-hold Bitcoin. The infrastructure works. Whether the agents themselves produce alpha remains unproven.
This article covers every infrastructure dimension for running these agents on a VPS: compute and memory requirements for cloud API versus local model inference, Python environment setup and persistent process management, broker API connections and WebSocket resilience, error recovery for stateful agents (which is qualitatively harder than EA crash recovery), security and API key management, and realistic cost-of-ownership calculations from $5/month experiments to $240/month multi-agent deployments.
This is not a guide to building a profitable trading strategy with LLMs. It is the plumbing: how to keep an autonomous agent running reliably on remote infrastructure, how much it costs, and what risk controls are non-negotiable before connecting any autonomous system to a live trading account.
Data is drawn from GitHub repository specifications, Forex VPS provider pricing verified as of Q1 2026, current LLM API pricing from OpenAI and Anthropic, broker API documentation (Alpaca, OANDA, Interactive Brokers, MetaAPI, CCXT), academic benchmarks (StockBench, arXiv survey of 27 papers), and the CFTC consumer advisory on AI trading claims. Where a figure comes from a single source or a commercially interested party, it is flagged.
What These Agents Actually Are, from an Infrastructure Standpoint
Autonomous trading agents built on frameworks like LangChain, AutoGPT, and CrewAI converge on a single architectural pattern called the ReAct loop: observe market data, reason with an LLM, decide on an action, execute via broker API, store results in memory, repeat. This loop runs as a persistent Python process on a server. Not as compiled code inside a trading platform. Not as a plugin or extension. A standalone application that happens to trade.
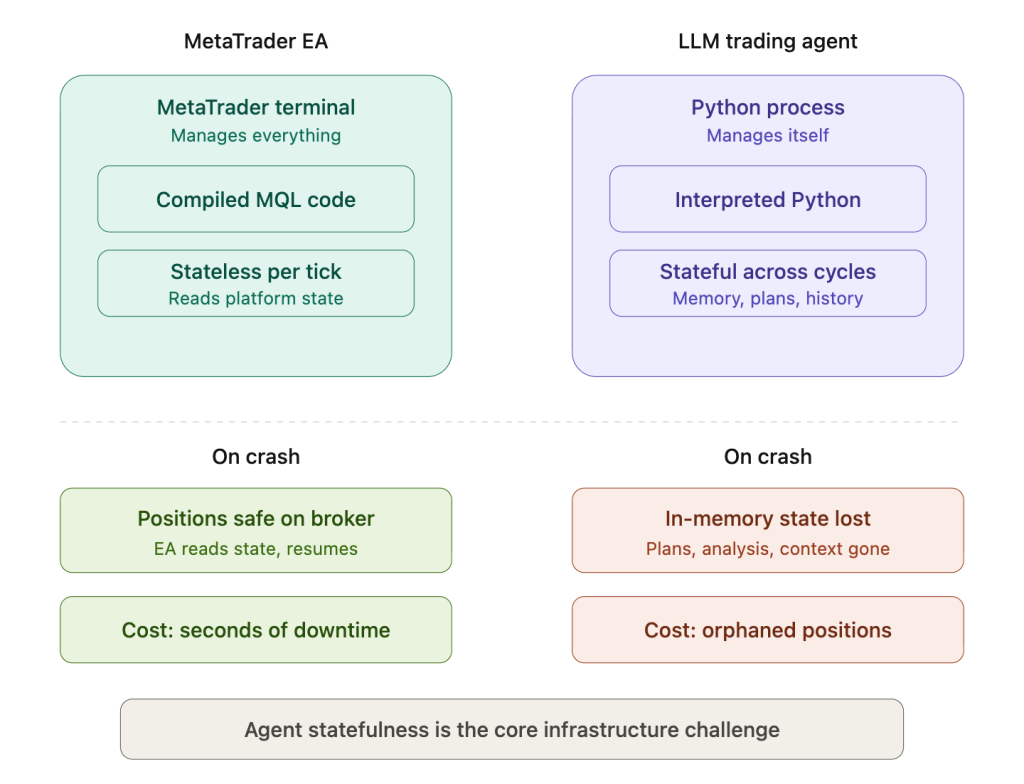
The infrastructure difference from MetaTrader EAs is fundamental, and understanding it prevents every configuration mistake that follows.
An EA runs as compiled MQL code inside the MetaTrader terminal, which manages positions, handles tick data, and provides the entire execution environment. The EA is essentially stateless per tick. It reads current platform state, applies its rules, and acts. If it crashes, MetaTrader still holds all positions on the broker’s server, and the EA simply restarts, reads the current state, and resumes. The crash costs processing time but not information.
An LLM agent maintains in-memory context: conversation history with the LLM, partial analysis results from multi-step reasoning, plans that span multiple decision cycles, and reasoning chains that inform the current action based on earlier conclusions. If the Python process dies mid-reasoning, all of that state vanishes unless it was explicitly checkpointed to disk before the crash. The agent restarts with no memory of what it was doing, what it had concluded, or what stage of a multi-step plan it had reached. Open positions may still exist on the broker, but the agent has no context for why they were opened or how they should be managed.
This statefulness difference is the single most important infrastructure fact for anyone deploying a trading agent on a VPS. Every process management, error recovery, and persistence decision in this article traces back to it.
The practical differences extend across every dimension. MetaTrader EAs use compiled MQL, a C-like language that executes in microseconds per tick. LLM agents use Python, an interpreted language with a rich ecosystem but fundamentally slower execution. EA decision latency is measured in microseconds. Agent decision latency is 1 to 30 seconds per LLM API call, depending on model complexity and prompt length. EAs operate on hardcoded rules and indicator calculations. Agents use chain-of-thought reasoning with dynamic tool selection. EAs consume price and volume data. Agents can ingest price data plus news feeds, sentiment analysis, SEC filings, social media, and any data source accessible via API. EA RAM footprint is 200 to 500 MB total for the MetaTrader terminal. Agent RAM footprint is 500 MB to 4 GB or more before any local model loading.
Three frameworks dominate the current landscape. LangChain’s LangGraph provides the most mature production implementation, with built-in state persistence, checkpointing at graph node boundaries, and human-in-the-loop gates that can require manual approval before executing trades above a threshold. CrewAI offers multi-agent collaboration with role-based personas, allowing separate analyst, trader, and risk manager agents to communicate via structured reports. AutoGPT evolved from a single autonomous agent into a platform with a visual workflow builder. All three require Python 3.10 or later as the runtime environment.
The Open-Source Landscape and Why None of It Is Production-Ready
Several notable projects demonstrate what the community has built, and understanding their capabilities and limitations prevents both unrealistic expectations and unnecessary reinvention.
TradingAgents is the most architecturally sophisticated project, with 29,900 GitHub stars and an Apache 2.0 license. Developed by researchers at UCLA and MIT, it deploys seven specialized agent roles: Fundamental Analyst, Sentiment Analyst, News Analyst, Technical Analyst, Bull Researcher, Bear Researcher, and Risk Manager. These agents communicate via structured reports rather than unstructured chat, which produces more consistent and auditable decision chains. The v0.2.0 release in February 2026 added multi-provider LLM support including GPT-5.x, Gemini 3.x, and Claude 4.x, plus Ollama integration for running local models. It uses Alpha Vantage for market data and requires no GPU because all inference happens via cloud APIs. Backtesting on simulated exchanges showed improved cumulative returns and Sharpe ratios versus baselines. However, no live broker integration exists. This is research software demonstrating an architecture, not a trading system you can connect to a brokerage account.
FinGPT at 18,800 stars is frequently cited in trading agent discussions but is not actually a trading agent. It provides open-source financial LLMs fine-tuned for sentiment analysis. Its Llama2-7B and 13B models fine-tuned with LoRA run on a single RTX 3090 and reportedly outperform GPT-4 on financial sentiment benchmarks. The infrastructure relevance is that these models can serve as a component within a larger trading agent, providing sentiment scoring at local inference cost rather than per-call API pricing.
AutoGPT at over 170,000 stars has the largest community but the least trading-specific infrastructure. Community-maintained plugins connect it to MT4/MT5 (Auto-GPT-MetaTrader-Plugin) and cryptocurrency wallets (Auto-GPT-Crypto-Plugin). Both plugins are community-maintained rather than officially supported, and their update status should be verified before deployment. The framework itself provides the general-purpose agent loop, but every trading-specific integration is third-party.
Several smaller projects connect LLMs to live brokers directly. A gpt-trading-agent project wires Perplexity and GPT-4o to Alpaca for US equity trading. A financial-analyst-crewai project uses CrewAI for Bitcoin analysis. One author who documented running a GPT-based agent on Alpaca for three months reported modest positive returns on small-cap stocks but actively intervened throughout the period. That intervention disqualifies it as evidence of autonomous profitability.
The academic evidence is more rigorous but sobering. The StockBench benchmark tested GPT-5, Claude 4 Sonnet, and other models as trading agents and found that LLM agents struggled to consistently outperform simple baselines, particularly in bearish markets. A large survey paper reviewing 27 academic papers found backtesting improvements of 15 to 30% over benchmarks but raised two structural warnings. First, herding risk: if multiple agents share similar training data and reasoning patterns, they may converge on the same positions, amplifying market moves rather than capturing independent alpha. Second, data contamination: LLMs trained on internet data have likely “seen” historical market outcomes during training, meaning backtesting on that same historical data may reflect memorization rather than genuine predictive ability.
The honest summary: the infrastructure for building and deploying trading agents is mature and well-documented. The agents themselves have not proven they can trade profitably without human intervention over meaningful time periods. This distinction matters for infrastructure planning because it means the most important investment is not compute power but risk controls, paper trading environments, and human oversight mechanisms.
Compute Requirements: Cloud API vs Local Inference
The single most important infrastructure decision is whether to call cloud LLM APIs or run models locally on the VPS. This choice determines whether you need a $4/month instance or a $300/month GPU server. Everything else, framework selection, broker integration, monitoring, is secondary to this binary.
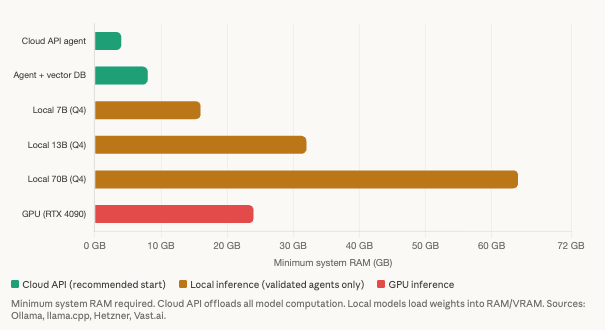
Cloud API agents need almost nothing from the local machine
An agent that sends prompts to GPT-4o, Claude, or any hosted LLM and receives responses via API offloads all inference computation to the provider’s data center. The VPS is responsible only for running the Python process, maintaining broker connections, storing data, and orchestrating the agent loop.
The Python interpreter itself consumes 6 to 7 MB at baseline. Importing pandas and numpy adds 50 to 80 MB. Loading LangChain with its tools brings the total to 200 to 500 MB. One year of 1-minute OHLCV bars for a single symbol (roughly 525,000 rows across 6 columns) adds approximately 25 MB. ChromaDB with 50,000 vectors at 768 dimensions for agent memory consumes 200 to 400 MB. The conversation buffer grows with history but remains modest if periodically summarized and pruned.
The typical total for a cloud-API agent is 500 MB to 2 GB of RAM. CPU utilization is minimal because the VPS spends most of its time waiting for API responses. A 2 vCPU instance with 4 GB RAM handles this workload comfortably with headroom for memory growth over multi-day operation.
Network bandwidth is negligible for API calls. One hundred LLM API calls per day generate under 1 GB of monthly transfer. Market data via WebSocket is more substantial: 20 concurrent streams at roughly 1 KB/second consume approximately 52 GB/month, but this is well within any standard VPS plan’s included traffic allocation.
Local model inference changes the picture entirely
Running a quantized model locally eliminates per-call API costs but demands dramatically more hardware. The requirements scale with model size in a predictable pattern.
A quantized 7B parameter model (Llama 3 via Ollama or llama.cpp at Q4 quantization) requires 4 to 5 GB of VRAM or system RAM for the model weights, plus 2 to 4 GB for the operating system, Python process, and agent overhead. That means 8 GB system RAM minimum and 16 GB recommended. A 13B model needs approximately 8 GB for weights alone, making 16 GB the minimum viable configuration. A 70B model requires 38 to 45 GB for Q4 quantized weights, pushing system requirements to 64 GB minimum. These are not configurations you run on a $4/month VPS.
Context window length dramatically affects RAM beyond the model weights themselves. A 7B Q4 model uses approximately 5 GB at a 2K context window but 10 to 12 GB at a 32K context window. An agent that sends long conversation histories or large market data summaries in each prompt can double its memory footprint from context alone.
CPU-only inference on VPS hardware is functional but slow. Memory bandwidth, not raw compute, is the bottleneck for LLM inference. Benchmarks show a 7B Q4 model generating 7 to 8 tokens per second on a Ryzen 3700X with DDR4 dual-channel memory. Typical shared VPS instances with limited memory bandwidth achieve only 2 to 5 tokens per second. For a trading agent that queries the model every 15 minutes with 500-token responses, that translates to 100 to 250 seconds of generation time per query. This is usable for periodic batch analysis where the agent evaluates market conditions on a schedule. It is painfully slow for anything that needs to respond to market events in real time.
GPU inference transforms the performance picture. An RTX 4090 pushes the same 7B model to 40 to 80 tokens per second, a 10 to 30x improvement over CPU. But GPU VPS instances cost $150 to $290/month for a continuous RTX 4090 (Vast.ai, RunPod), and A100 40GB instances run $290 to $1,030/month. For most trading agents using cloud APIs, GPU infrastructure is unnecessary and wasteful.
The practical recommendation is straightforward. Start with cloud APIs on a minimal VPS. GPT-5 nano and GPT-4o-mini cost fractions of a cent per call. If API latency or cost becomes a constraint after months of live testing on paper accounts, evaluate local inference on a larger instance. Do not pre-optimize for local inference before confirming the agent is worth running at all. The infrastructure to experiment costs $5/month. The infrastructure for local 7B inference costs $32/month minimum. The infrastructure for serious GPU inference costs $150+/month. Match the investment to the evidence of profitability, which at this stage of the technology is limited.
Python Environment and Persistent Process Management
Trading agents need to run as persistent, auto-restarting processes, not as scripts launched in a terminal session that dies when the SSH or RDP connection closes. The setup differs significantly between Windows and Linux, and the choice of operating system matters more for Python agents than it does for MetaTrader EAs.
Windows VPS setup
Install Python via the official installer from python.org or via Miniconda. During installation, always check “Add python.exe to PATH” and “Disable path length limit,” both of which prevent common deployment failures. Create isolated virtual environments per agent with python -m venv to prevent dependency conflicts. An agent using LangChain and CCXT may require different package versions than one using CrewAI and Alpaca’s SDK. Isolation prevents one agent’s upgrade from breaking another.
Key packages for a typical trading agent include langchain, openai, anthropic, ccxt, pandas, numpy, websocket-client, and chromadb. Installing TA-Lib on Windows is notoriously difficult because it requires a pre-compiled C library that pip cannot install natively. The two reliable paths are conda install from the conda-forge channel or downloading pre-built Windows wheels from Christoph Gohlke’s repository.
NSSM (Non-Sucking Service Manager) is the standard tool for running Python scripts as Windows services. Despite its last release being v2.24 in 2014, it remains the de facto solution because it works reliably and nothing has displaced it. Installation is a single portable executable with no setup required. Register a trading agent with a command pointing NSSM to the virtual environment’s Python executable and the agent’s main script. Configure stdout and stderr logging with rotation at 10 MB to prevent disk exhaustion. Set restart behavior to restart on exit with a 5-second delay between attempts. NSSM automatically throttles restart attempts if the application fails within 10 seconds of launching, scaling up to 4-minute delays to prevent crash loops that burn through API credits.
Linux VPS setup
On Linux, systemd is the correct tool for persistent process management. A service unit file specifies the Python binary from the virtual environment as the executable, with Restart=always and RestartSec=10 to handle crashes. StartLimitBurst=5 combined with StartLimitIntervalSec=300 allows a maximum of 5 restarts within 5 minutes before systemd stops trying, preventing infinite restart loops when the underlying problem (a revoked API key, a broker outage, a corrupted state file) requires human intervention rather than automated restarts.
Environment variables load from an .env file via the EnvironmentFile directive, keeping API keys out of the service configuration. Always set PYTHONUNBUFFERED=1 in the environment so that log output appears in real time via journalctl rather than buffering in Python’s stdout, which can delay crash diagnosis by minutes.
Docker for multi-agent deployments
Docker provides the best isolation and reproducibility when running multiple agents or combining an agent with supporting services. A typical Dockerfile starts from python:3.12-slim, installs system dependencies (gcc for TA-Lib compilation), copies requirements.txt for dependency layer caching, and runs the agent as a non-root user for security.
Docker Compose orchestrates multi-container architectures elegantly. A data-feed service, one or more strategy agents, a risk manager, and a monitoring dashboard each run in separate containers with shared volumes for market data and logs. Container overhead is minimal at 10 to 50 MB RAM each, and the isolation guarantees that one agent’s crash or memory leak cannot affect another.
Why Linux wins for Python agent workloads
Linux idles at 600 MB to 1 GB of RAM versus 1.8 to 4 GB for Windows Server, freeing 1 to 2 GB for the actual agent on the same plan. Docker runs natively on Linux versus requiring Docker Desktop or WSL2 on Windows, both of which add overhead and complexity. TA-Lib installs trivially via apt on Linux versus the painful Windows workarounds described above. Celery, the most widely used Python task queue for scheduling periodic analysis jobs, officially does not support Windows.
The only reason to choose a Windows VPS for an agent workload is if MetaTrader must run alongside the agent on the same machine, for instance when the agent generates signals that a MetaTrader EA executes. Even this requirement can be eliminated: MetaAPI provides a cloud-hosted bridge that exposes MT4/MT5 broker accounts via REST and WebSocket APIs accessible from any Linux server running Python. Unless your workflow specifically requires a local MetaTrader terminal, Linux is the correct choice for autonomous trading agents. The RAM savings alone can drop you an entire VPS tier.
Broker API Connections
Five broker APIs dominate the trading agent ecosystem. Each has distinct infrastructure requirements, rate limits, and deployment quirks that affect how the agent runs on a VPS.
Alpaca is the most popular choice for agent projects. Nearly every open-source trading agent surveyed integrates it. The API is commission-free for US equities and cryptocurrency, offers both REST and WebSocket endpoints, and provides a dedicated paper trading environment at a separate API endpoint. Rate limits are 200 requests per minute per API key, with burst capacity of roughly 10 requests per second. Authentication uses two headers: an API key ID and a secret key. A critical infrastructure limitation that catches many developers: only one WebSocket connection per account is allowed. Multi-strategy setups that need separate data streams for different agents require the alpaca-proxy-agent workaround, which multiplexes a single upstream connection to multiple local consumers.
OANDA v20 serves forex and CFD traders with a REST API for order management and a streaming endpoint for real-time prices. Rate limits are generous at 120 requests per second per IP, with up to 20 concurrent streaming connections. Authentication uses a bearer token generated in the Account Management Portal. OANDA explicitly recommends HTTP 1.1 keep-alive connections to avoid the overhead of establishing a new TCP handshake per request. For an agent making frequent position checks or order modifications, this recommendation translates directly to lower latency and reduced network overhead on the VPS.
Interactive Brokers offers the most powerful but most complex integration. Unlike the REST APIs above, IB uses a proprietary TCP socket protocol that requires either TWS (Trader Workstation) or IB Gateway running as a separate Java process on the VPS. IB Gateway is the lighter option at roughly 40% fewer resources than TWS, connecting on port 4001 for live accounts or 4002 for paper trading. Rate limits are strict: 50 messages per second maximum, with historical data limited to 60 requests per 10 minutes and a 10 to 15 minute penalty box for pacing violations. Running headless on Linux requires Xvfb (X Virtual Framebuffer) to simulate a display that the Java GUI expects, plus IBC (IB Controller) from GitHub to automate login and handle the mandatory daily restart that IB enforces. The Python library has transitioned from ib_insync to its actively maintained fork ib_async (v2.1.0). Budget 4 GB minimum RAM for the Gateway process to prevent crashes during bulk data requests.
MetaAPI bridges the gap between Python agents and MetaTrader brokers. It runs MT4/MT5 terminal instances in their cloud infrastructure, exposing REST and WebSocket APIs that any language can consume. The Python SDK handles connection management. This is the critical tool for traders who want LLM agent intelligence applied to existing MT4/MT5 broker accounts without running a local MetaTrader terminal. It eliminates the Windows VPS requirement entirely for this use case.
CCXT provides a unified API across 108+ cryptocurrency exchanges including Binance, Coinbase, Kraken, Bybit, and OKX. The same create_market_buy_order() call works across all supported exchanges. Built-in rate limiting auto-throttles requests per exchange specifications, and standardized exceptions for rate limit violations and network errors simplify error handling. For crypto-focused agents, CCXT eliminates the need to learn each exchange’s individual API.
WebSocket connection management requires explicit engineering
Connections drop due to network issues, server maintenance, and inactivity timeouts. MetaTrader handles reconnection natively and invisibly. Broker API WebSocket connections do not. The agent code must handle this explicitly.
The standard pattern is exponential backoff with jitter: reconnect after 1 second, then 2, 4, 8 seconds, doubling up to a 60-second maximum, with random jitter added to each interval to prevent synchronized retry storms when multiple agents on the same VPS reconnect simultaneously after a network interruption.
After reconnection, the agent must re-subscribe to all data channels and reconcile its position state with the broker. A naive agent that reconnects and resumes without checking positions may not know that a limit order filled during the disconnection, leading to duplicate entries or unmanaged positions. This reconciliation step is something MetaTrader EAs never need because the platform handles it natively. For autonomous agents, it must be explicitly coded and tested, including testing for the case where the broker’s position state diverges from the agent’s last known state.
Error Recovery: The Hardest Infrastructure Problem
Agent crashes are qualitatively different from EA crashes, and the difference determines whether a crash costs seconds or money.
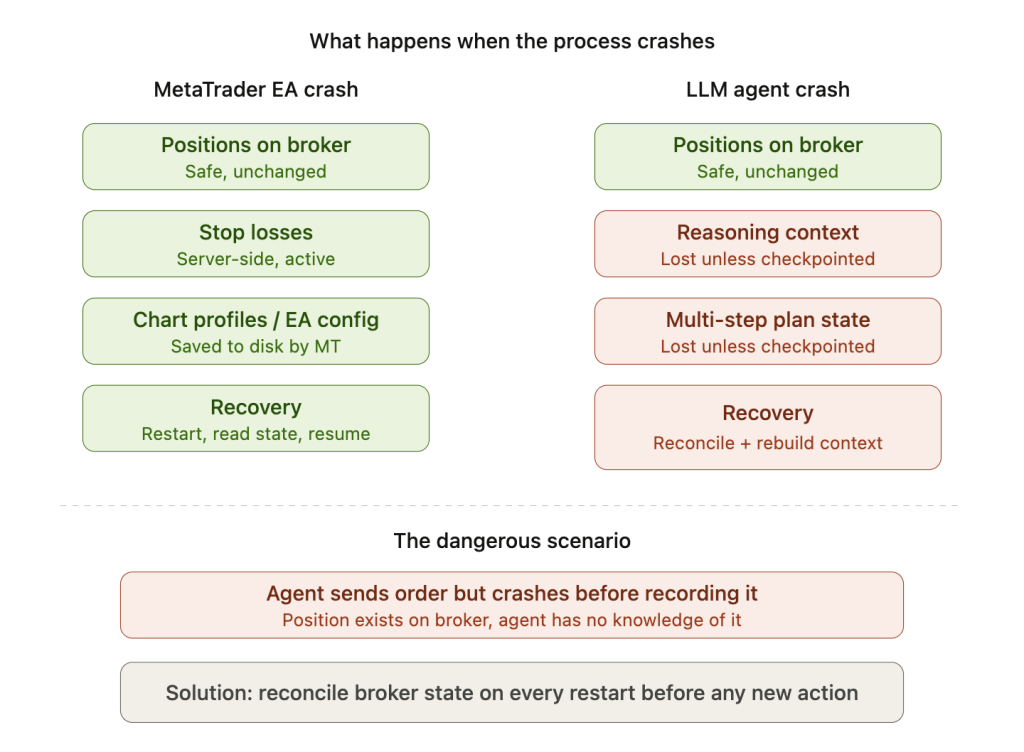
When a MetaTrader EA crashes mid-tick, the terminal still holds all positions on the broker’s server. The EA restarts, reads the current platform state (open positions, pending orders, account balance), and resumes operating. The crash costs a few seconds of processing time. No information is permanently lost because MetaTrader is the system of record.
When an agent crashes mid-reasoning, the consequences are worse in three specific ways. First, all in-memory state vanishes: the conversation history that informed the current decision, the partial analysis results from a multi-step evaluation, the reasoning chain that led to a position entry decision. Second, if the agent sent an order to the broker but crashed before recording it locally, it restarts with no knowledge of that position. Third, if the agent was partway through a multi-step execution plan (enter position, set stop loss, set take profit, configure alerts), a crash after step one but before step two leaves a position with no stop loss until the agent recovers and reconciles.
Framework-level checkpointing
LangGraph’s built-in checkpointing is the most mature framework-level solution. It snapshots the agent’s graph state at every node boundary, organized by a thread ID that identifies the conversation or decision chain. Production implementations use PostgresSaver for persistence that survives both process restarts and server reboots, with optional EncryptedSerializer for sensitive trading data like position sizes and account identifiers.
The critical limitation: checkpoints occur between graph nodes, not mid-node. If a node contains multiple operations (analyze market conditions, decide on entry, calculate position size, send order), a crash partway through loses all work in that node. The design principle is to make each node atomic: one meaningful action per node. A node that sends an order should do only that. A node that calculates position size should do only that. This granularity means a crash loses at most one node’s work, and the agent can resume from the last completed checkpoint.
Custom state persistence for agents outside LangGraph
For agents built without LangGraph’s checkpointing, the pattern is atomic JSON state writes. Serialize the agent’s critical state (open positions as the agent understands them, daily profit and loss, circuit breaker status, last analysis timestamp, current stage in any multi-step plan) to a temporary file, then use os.replace() to perform an atomic rename over the permanent state file. This two-step process prevents corruption from mid-write crashes: either the old file exists intact or the new file does. There is no intermediate state where the file is partially written.
Freqtrade, a mature open-source trading framework that predates the LLM agent wave, uses SQLite for all trade state persistence, including position tracking and stop-loss reinitialization on restart. This approach is worth studying even for LLM-based agents because it solves the same fundamental problem: maintaining a reliable system of record that survives process death.
Circuit breakers prevent cascading failures
When external APIs go down, a naive agent retries indefinitely, burning time, compute, and potentially API credits on requests that cannot succeed. The PyBreaker library implements the standard three-state circuit breaker pattern: Closed (normal operation, requests pass through), Open (after N consecutive failures, all requests fail immediately without attempting the call), and Half-Open (after a timeout, one probe request is allowed to test whether the service has recovered).
Deploy separate circuit breakers for each external service. One for the LLM API. One for the broker API. One for market data. When the LLM circuit breaker trips, the agent should fall back to simpler rule-based logic or pause new trades entirely, not spin in infinite retry loops. When the broker circuit breaker trips, the agent should stop attempting trades and alert the operator. When market data trips, the agent should freeze all analysis until data resumes.
The infinite loop risk is specific to autonomous agents
An agent stuck retrying a failed LLM call can burn through an entire API budget in minutes. Each failed request may still count toward token billing depending on where in the API pipeline the failure occurs. Prevention requires multiple hard limits working together: a max_retries parameter on every API call (3 to 5 is typical), circuit breakers as described above, a maximum number of LLM calls per decision cycle (capping at 5 prevents runaway multi-step reasoning), and a total timeout budget per analysis cycle (120 seconds is a reasonable ceiling for a single trading decision).
Alerting: know when something breaks before checking manually
Telegram bot notifications are the community standard for trading agent alerting. A simple HTTP POST to the Telegram Bot API sends alerts for agent crashes, daily loss limit triggers, circuit breaker trips, trade executions, and successful restarts. Setup requires creating a bot via Telegram’s @BotFather and obtaining a chat ID. Total implementation is under 10 lines of Python. Discord webhooks offer an alternative with even simpler setup for developers already in Discord-based trading communities.
The monitoring philosophy for agents differs from EAs. With a MetaTrader EA, the primary concern is “is MetaTrader running.” With an autonomous agent, the concerns are layered: is the Python process running, is it connected to the broker, is it connected to the LLM provider, is it receiving market data, has it made a trading decision recently, and is its state file current. A heartbeat that covers all of these layers provides genuine monitoring. A process check that only confirms the Python PID exists misses every failure mode that matters.
VPS Sizing, Provider Costs, and Total Cost of Ownership
Verified pricing as of Q1 2026 shows dramatic variation between providers for equivalent specifications. The choice of provider matters as much as the choice of plan tier for Python agent workloads.
A cloud-API-only agent (the most common starting configuration) needs 2 vCPU and 4 GB RAM with 40 GB SSD storage. Hetzner’s CX22 instance handles this at approximately $4/month. The equivalent on DigitalOcean costs roughly $24/month. On AWS, a t4g.large (2 vCPU, 8 GB) runs approximately $49/month on-demand. Hetzner delivers 3 to 7x better value than competitors for equivalent specifications on pure compute workloads. The tradeoff is fewer data center locations and less extensive managed service options, neither of which matters for a trading agent that primarily needs CPU, RAM, and outbound internet access.
An agent with a vector database and heavier data processing needs 4 vCPU and 8 GB RAM. Hetzner’s CX32 serves this at roughly $7/month versus $48/month on DigitalOcean. This tier accommodates ChromaDB with 50,000+ vectors, a year of market data in memory, and the agent framework with comfortable headroom.
An agent running a local 7B model on CPU needs 16 vCPU and 32 GB RAM. Hetzner’s CX52 at approximately $32/month is the most cost-effective option. This provides enough memory for a Q4 quantized 7B model plus the agent stack, though inference will be slow at 2 to 5 tokens per second on shared VPS hardware.
GPU inference for serious local model deployment requires dedicated GPU instances. Hetzner does not offer GPU cloud. Vast.ai and RunPod provide RTX 4090s at $0.20 to $0.40 per hour, translating to $150 to $290/month for continuous operation. A100 40GB instances run $0.40 to $1.42 per hour, or $290 to $1,030/month. These costs are justified only after an agent has demonstrated consistent performance on paper accounts using cloud APIs.
A Windows VPS costs $5 to $10/month more than the Linux equivalent due to OS licensing, adding $60 to $120 per year with no benefit for pure Python workloads. This is dead cost for any agent that does not require a local MetaTrader terminal.
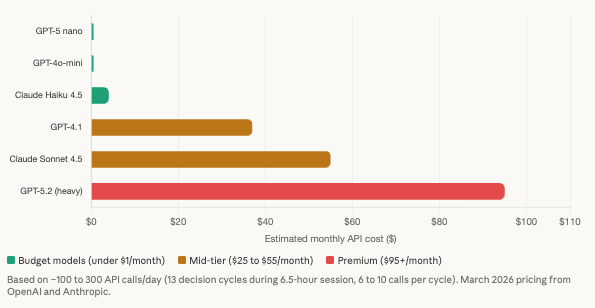
LLM API costs have dropped to the point of irrelevance for most configurations
Current pricing per million tokens makes even frequent agent operation remarkably affordable. GPT-5 nano runs $0.05 input and $0.40 output per million tokens. GPT-4o-mini costs $0.15 and $0.60. GPT-4.1 costs $2 and $8. Claude Haiku 4.5 costs $1 and $5. Claude Sonnet 4.5 costs $3 and $15.
A multi-agent trading decision in the TradingAgents style with 7 specialized roles consumes 6 to 10 LLM calls totaling 15,000 to 30,000 tokens per decision cycle. A conservative agent checking markets every 30 minutes during a 6.5-hour trading session makes roughly 13 cycles per day, approximately 100 API calls and 250,000 tokens daily. At GPT-5 nano pricing, that costs roughly $0.50/month. At GPT-4.1, approximately $37/month. At Claude Sonnet 4.5, approximately $55/month.
Prompt caching, available from both OpenAI and Anthropic, reduces repeated input costs by up to 90%. This is significant for agents that send similar system prompts and market context on every call. Batch API discounts of 50% apply to non-time-sensitive analysis tasks like end-of-day portfolio review.
Total cost of ownership across realistic scenarios
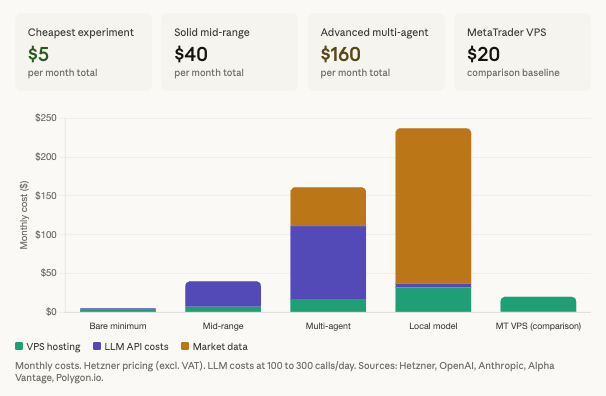
A bare minimum experiment, a single cloud-API agent on Hetzner calling GPT-5 nano with free-tier market data, costs approximately $5 to $6/month. This is the entry point for a trader who wants to test whether LLM-based analysis adds value to their decision-making before committing to more infrastructure.
A solid mid-range agent on Hetzner’s 4 vCPU plan calling GPT-4.1 with broker-provided market data costs approximately $35 to $50/month. This supports a production-quality agent with vector memory, multiple data sources, and a capable reasoning model.
An advanced multi-agent deployment with specialized roles on Hetzner’s 8 vCPU plan, a premium LLM like GPT-5.2, and paid market data from Alpha Vantage costs approximately $160/month. This is the upper range for cloud-API-based architectures.
A local model deployment with paid data, running a 7B model on a 32 GB Hetzner instance with supplementary API calls and a Polygon.io data subscription, costs approximately $240/month. This configuration makes sense only for traders who need complete data privacy or who have validated their agent’s performance and want to eliminate per-call API costs.
For comparison, a traditional MetaTrader VPS running EAs costs $15 to $30/month with zero API costs and zero market data costs because MetaTrader provides both execution and data through the broker connection.
The break-even math deserves explicit attention. On a $10,000 trading account, $200/month in infrastructure costs requires a 24% annual return just to cover the infrastructure before any profit. On a $50,000 account, that drops to a more manageable 4.8%. On a $100,000 account, it is 2.4%. The infrastructure cost is modest for serious capital but creates significant drag on small accounts. A trader with a $5,000 account experimenting with a $160/month multi-agent setup is spending 38% of their capital annually on infrastructure alone.
Security Requires Defense in Depth
Trading agents connect to more external services than MetaTrader EAs, and each connection introduces a credential that must be protected. A typical agent holds API keys for the LLM provider, the broker, one or more market data services, and possibly a vector database or monitoring service. A single compromised key can drain an API budget, execute unauthorized trades, or exfiltrate trading data.
API key management
At minimum, store all keys in .env files loaded via the python-dotenv library, with .env added to .gitignore immediately upon project creation. On Linux, restrict file permissions with chmod 600 .env so only the file owner can read it. On Windows, NSSM’s AppEnvironmentExtra registry value stores keys outside the codebase entirely, loading them into the process environment at service start.
Never hardcode API keys in source code. This sounds obvious but remains the most common security failure in open-source trading agent repositories. GitHub actively scans for exposed API keys in public repositories, and OpenAI auto-revokes keys found in public commits. A key committed even briefly to a public repo should be considered compromised and rotated immediately, because automated scanners operate within minutes of the commit.
Broker API permission scoping
Alpaca offers the most granular permission control among the commonly used broker APIs: custom per-scope permissions where orders, positions, and account access can each be independently set to read-write, read-only, or no-access, with optional expiration dates on each key. Always disable withdrawal permissions on API keys used by automated agents. An agent needs to place and manage trades. It never needs to withdraw funds.
Use paper trading environments exclusively during development and initial testing. Alpaca, OANDA, and Interactive Brokers all provide separate paper endpoints that use the same API structure as live accounts. There is no infrastructure reason to develop against a live account, and every financial reason not to.
Risk controls must be implemented in code, not delegated to the LLM
This point deserves emphasis because it contradicts how many tutorials frame agent design. An LLM should not decide position sizes, evaluate whether a loss limit has been reached, or determine whether trading should continue after a series of losses. These are deterministic rules that must execute reliably regardless of what the LLM reasons, hallucinates, or suggests. Implement them as hard-coded Python checks that run before any order is submitted to the broker.
Position size limits should enforce a hard cap at 2% of account equity per trade with an absolute dollar maximum as a secondary ceiling. Daily loss limits should halt all trading automatically when cumulative daily profit and loss exceeds negative 3% of account value. A kill switch implemented as a file-based toggle should close all positions and cancel all orders when activated, and it must be activatable remotely (via Telegram command, a simple HTTP endpoint, or even the presence of a specific file on the VPS). Order rate limiting at a maximum of 1 order per 30 seconds prevents rapid-fire mistakes from reasoning errors or retry loops. Price validation should reject any order with a price that deviates significantly from the current market, catching hallucinated price levels before they reach the broker.
The FIA (Futures Industry Association) best practices for algorithmic trading mandate all of these controls plus stale data detection (rejecting data older than N seconds) and hard price limits (maximum and minimum prices the algorithm will ever trade at). These are not theoretical recommendations. They are the minimum standard for any automated system connected to a live account.
LLM API spending limits
An agent stuck in a retry loop or a runaway reasoning chain can burn through hundreds of dollars of API credits in minutes if spending is uncapped. Set hard monthly limits in the OpenAI dashboard’s Billing section. Implement per-request token limits via the max_tokens parameter on every API call. Monitor cumulative spending with tools like reGuard (hard spending limits across providers with threshold alerts) or OpenRouter (unified billing across 290+ models with per-model caps). These are not optional safety measures. They are the API equivalent of a stop loss: defining the maximum you are willing to lose before the system halts.
VPS network security
On Linux, configure UFW (Uncomplicated Firewall) to deny all incoming traffic except SSH. Disable password authentication in the SSH configuration and use key-based authentication exclusively. Install Fail2ban to automatically block IP addresses after repeated failed login attempts. One VPS operator documented 145 failed SSH login attempts in the first week of deployment, all from automated scanners probing for weak credentials. This is not unusual. It is the default experience of any VPS with a public IP address.
On Windows, change the default RDP port from 3389 to a non-standard port, enable Network Level Authentication, and restrict RDP access to specific trusted IP addresses. The default RDP port is continuously probed by automated botnets, and leaving it unchanged with password authentication is an invitation to compromise.
An Honest Assessment This Technology Demands
The infrastructure for running autonomous trading agents on a VPS is mature, well-documented, and remarkably affordable. The technology gap is not in the infrastructure. It is in the agents themselves.
What LLM trading agents genuinely do well
They synthesize diverse information sources into coherent analysis. A single agent can ingest an earnings report, a Reuters headline, a technical indicator reading, a sentiment score from social media, and a macroeconomic data point, then produce a structured assessment that weighs all of these inputs against each other. No human trader processes this breadth of information simultaneously, and no traditional EA can consume unstructured text data at all.
They generate natural-language reasoning about trade decisions that aids human oversight. An agent that explains “I am considering a short position on EUR/USD because the NFP print exceeded expectations by 2 standard deviations, the 4-hour RSI is overbought at 78, and sentiment on EUR has turned negative in the last 90 minutes” provides more auditable decision-making than an EA that simply fires a signal. This transparency has genuine value for traders who want to understand and validate their system’s logic.
They adapt to new information types without retraining. Adding a new data source (a central bank speech transcript, a supply chain disruption report, a regulatory filing) requires a prompt modification, not a code rewrite. This flexibility is real and meaningful for traders whose edge depends on information synthesis rather than pure speed.
What they cannot do
Consistently generate trading profits. No independently verified, long-term track record exists for any LLM-based trading agent. The StockBench benchmark tested GPT-5, Claude 4 Sonnet, and other models as trading agents and found they struggle to consistently outperform simple baselines, particularly in bearish markets where buy-and-hold fails and active management supposedly adds value. In the Alpha Arena live trading competition, only 2 of 6 tested LLMs beat buy-and-hold Bitcoin, and GPT-5 and Gemini both lost more than 25% of their starting capital.
The one author who documented genuine results over three months with an LLM agent on Alpaca reported modest positive returns on small-cap stocks but actively intervened throughout the period. This is decision support with a human in the loop, not autonomous trading. The distinction matters because the infrastructure requirements for a decision-support tool (occasional API calls, no persistent process management, no circuit breakers) are dramatically simpler than for a fully autonomous agent.
Hallucination risk is severe and specific to this application
OpenAI’s own testing found that o3 and o4-mini models hallucinated 30 to 50% of the time on certain evaluation benchmarks. In a trading context, hallucination means an LLM confidently stating fabricated market analysis: misinterpreting earnings numbers, inventing price targets that no analyst published, confusing correlation with causation in historical patterns, or generating technical analysis of a chart pattern that does not exist in the actual data.
Cross-verification of all LLM outputs against actual data sources is not optional. It is essential. An agent that acts on LLM reasoning without verifying the underlying facts against real market data is trading on potentially fabricated information. The infrastructure implication is that agents need a verification layer between LLM output and order execution, adding complexity and latency but preventing the most dangerous failure mode.
Latency disqualifies entire strategy categories
A single LLM API call takes 1 to 10+ seconds. A full multi-agent decision cycle with seven specialized roles takes 30 to 120 seconds. Traditional algorithmic trading on MetaTrader executes in milliseconds. LLM agents are fundamentally unsuitable for scalping, market making, news reaction trading, or any strategy where entry timing within seconds affects the outcome.
The viable strategy categories are swing trading (holding hours to days), position trading (holding days to weeks), and daily portfolio rebalancing, timeframes where minutes of decision time are irrelevant to the outcome. An agent that takes 90 seconds to decide on a position entry for a trade targeting 50 pips over the next two days loses nothing from that decision latency. The same agent attempting to scalp a 3-pip move on M1 is structurally incapable of competing.
Regulatory and fraud context
The CFTC has issued an explicit consumer advisory warning that “AI technology can’t predict the future or sudden market changes” and that “fraudsters are exploiting public interest in AI to tout automated trading algorithms.” Claims of autonomous AI systems “crushing the market” that appear in Medium posts and social media invariably trace back to cherry-picked time periods, survivorship bias, or commercial products selling subscriptions.
Using an LLM does not change regulatory requirements for the trader. The same rules apply whether a trade is initiated by a manual click, an MQL4 EA, or a Python script calling GPT-4o. The broker handles exchange compliance and reporting. If managing other people’s money, investment advisor registration applies regardless of AI involvement. In the EU, MiFID II requires algorithmic trading firms to maintain resilient systems, risk controls, and kill switches. These requirements are simply good engineering practice regardless of whether regulation mandates them.
The practical recommendation
Start on paper trading accounts exclusively. Treat every LLM output as potentially hallucinated until verified against actual data. Implement every risk control described in the security section before connecting to a live account. And recognize that the most valuable near-term application is not autonomous trading but LLM-augmented decision support, where the agent researches, synthesizes, and recommends while a human makes the final call. The infrastructure for this use case is simple (a cloud API agent on a $5/month VPS), the risk is contained (the human decides whether to act), and the value is immediate (broader information synthesis than manual research provides).
FAQ
Can I run a trading agent on a Windows VPS alongside MetaTrader?
Yes, but the resource requirements compound. MetaTrader with a few charts and EAs consumes 400 to 800 MB. The Python agent with LangChain and a vector database consumes 500 MB to 2 GB. Windows Server takes 1.2 to 1.8 GB. Total demand is 2.1 to 4.6 GB before any headroom. A 4 GB Windows VPS is tight. An 8 GB plan provides the headroom that prevents performance degradation during volatile periods when both the EA and the agent are active simultaneously. The better architectural choice for most setups is to eliminate the Windows requirement entirely by using MetaAPI to bridge the agent to your MT4/MT5 broker account from a Linux VPS, which frees 1 to 2 GB of RAM from the OS alone.
How do I keep the agent running when I close my SSH or RDP session?
On Linux, register the agent as a systemd service. The service runs independently of your terminal session and survives both session disconnects and server reboots. On Windows, register the agent as a Windows service using NSSM. Both approaches provide automatic restart on crash, logging, and integration with the operating system’s process management. Running an agent in a terminal window via SSH or RDP means the process dies when the connection closes. This is the single most common deployment mistake for developers coming from a local development workflow.
What happens to my open positions if the agent crashes?
Open positions remain on the broker’s server. The broker does not close positions because your agent disconnected. The danger is not position loss but position management loss. If the agent placed a trade with the intention of setting a stop loss in a subsequent step and crashed between those steps, the position exists on the broker with no stop loss. On restart, the agent must reconcile its local state with the broker’s position state before taking any new action. This reconciliation step is the first thing the agent should execute after initialization, and it must handle the case where positions exist that the agent has no record of. The risk control recommendation from the security section applies here: never submit an order without a stop loss in the same API call or in an immediately subsequent call with error handling that closes the position if the stop loss placement fails.
Is GPT-4o or Claude better for trading agents?
From an infrastructure perspective, the differences are minimal. Both accept the same prompt structures, both return responses in 1 to 10 seconds, both charge per token with similar pricing at equivalent capability tiers. The practical differences are in reasoning quality (which varies by task and changes with each model update), context window size (which affects how much market data you can include per call), and tool-use reliability (which determines how consistently the model calls your broker functions with correct parameters). The honest answer is that no model has demonstrated consistent trading profitability in independent testing, so the choice between providers matters less than the choice of risk controls, verification layers, and human oversight. Start with whichever provider offers the cheapest capable model (GPT-5 nano or GPT-4o-mini at current pricing) and upgrade only if you identify specific reasoning failures that a more capable model resolves.
Do I need a GPU VPS for a trading agent?
Almost certainly not. If your agent uses cloud APIs for LLM inference (which is the recommended starting configuration), the VPS performs no model computation at all. A 2 vCPU instance with 4 GB RAM handles the full workload. GPU instances become relevant only if you run local model inference to eliminate per-call API costs or to maintain data privacy, and even then only after you have validated the agent’s performance on paper accounts using cloud APIs. A GPU VPS at $150 to $290/month for an agent that has not demonstrated profitability on a $4/month cloud-API setup is spending 30 to 70x more on infrastructure for an unvalidated strategy.
How do I test an agent safely before risking real money?
Every broker API covered in this article provides a paper trading environment: Alpaca’s paper endpoint, OANDA’s practice account, Interactive Brokers’ paper trading mode. These use the same API calls, the same data feeds, and the same order types as live accounts. The agent code is identical. Only the endpoint URL and API key differ. Run the agent on paper for a minimum of three months across different market conditions (trending, ranging, volatile) before considering live deployment. Monitor not just profitability but also behavior: does the agent handle weekends and market holidays gracefully, does it recover correctly from API outages, does the circuit breaker trip and reset as expected, does memory usage remain stable over weeks of continuous operation. Infrastructure reliability must be proven before strategy profitability is even evaluated.
References
- GitHub Repositories. TradingAgents (TauricResearch/TradingAgents, 29,900 stars, Apache 2.0): seven specialized agent roles, v0.2.0 February 2026 with multi-provider LLM support, Alpha Vantage data, no live broker integration. FinGPT (AI4Finance-Foundation/FinGPT, 18,800 stars): financial sentiment LLMs, Llama2-7B/13B with LoRA. AutoGPT (170,000+ stars): Auto-GPT-MetaTrader-Plugin (community-maintained), Auto-GPT-Crypto-Plugin (community-maintained). gpt-trading-agent (Perplexity + GPT-4o + Alpaca). financial-analyst-crewai (CrewAI for BTC analysis). PyBreaker circuit breaker library. IBC (IB Controller) for headless Interactive Brokers Gateway automation.
- Academic Research. StockBench (arXiv:2510.02209): LLM agents tested as trading agents, struggle to consistently outperform simple baselines, particularly in bearish markets. Survey paper (arXiv:2408.06361, updated March 2026): review of 27 papers, 15 to 30% backtesting improvements over benchmarks, herding risk from shared training data, data contamination from LLMs having seen historical market outcomes during training. Alpha Arena live trading competition: 2 of 6 LLMs beat buy-and-hold Bitcoin, GPT-5 and Gemini lost 25%+.
- LLM Provider Documentation and Pricing (March 2026). OpenAI: GPT-5 nano ($0.05/$0.40 per million tokens), GPT-4o-mini ($0.15/$0.60), GPT-4.1 ($2/$8), GPT-4o ($2.50/$10). Anthropic: Claude Haiku 4.5 ($1/$5), Claude Sonnet 4.5 ($3/$15), Claude Opus 4.5 ($5/$25). Prompt caching reducing repeated input costs by up to 90%. Batch API 50% discount for non-time-sensitive tasks. OpenAI hallucination testing: o3 and o4-mini models hallucinated 30 to 50% on certain benchmarks.
- Broker API Documentation. Alpaca: commission-free US equities and crypto, 200 requests/minute, one WebSocket per account, alpaca-proxy-agent for multiplexing, granular per-scope permissions with expiration. OANDA v20: 120 requests/second, 20 concurrent streams, HTTP 1.1 keep-alive recommended. Interactive Brokers: TWS/IB Gateway (ports 4001/4002), 50 messages/second, 60 historical requests per 10 minutes, 10 to 15 minute penalty box, ib_async v2.1.0, 4 GB minimum RAM for Gateway. MetaAPI: cloud-hosted MT4/MT5 terminals with REST and WebSocket APIs, Python SDK metaapi-cloud-sdk v29.1.1. CCXT: unified API for 108+ cryptocurrency exchanges with built-in rate limiting.
- VPS Provider Pricing (Q1 2026, excluding VAT where applicable). Hetzner: CX22 (2 vCPU/4 GB) approximately $4/month, CX32 (4 vCPU/8 GB) approximately $7/month, CX52 (16 vCPU/32 GB) approximately $32/month. DigitalOcean: equivalent 2 vCPU/4 GB approximately $24/month, 4 vCPU/8 GB approximately $48/month. AWS: t4g.large (2 vCPU/8 GB) approximately $49/month on-demand. Vultr: $15 to $80/month for comparable tiers. GPU instances: Vast.ai and RunPod RTX 4090 at $0.20 to $0.40/hour ($150 to $290/month continuous), A100 40GB at $0.40 to $1.42/hour ($290 to $1,030/month). Windows VPS licensing premium: $5 to $10/month over Linux equivalent.
- Agent Frameworks. LangChain/LangGraph: built-in state persistence, checkpointing at graph node boundaries via PostgresSaver, EncryptedSerializer for sensitive data, human-in-the-loop gates. CrewAI: multi-agent collaboration with role-based personas. AutoGPT: visual workflow builder, evolved from single autonomous agent to platform.
- Process Management Tools. NSSM (Non-Sucking Service Manager) v2.24: Windows service registration for Python scripts, log rotation, automatic restart with configurable delay, crash loop throttling. systemd: Linux service management with Restart=always, RestartSec, StartLimitBurst/IntervalSec. Docker: python:3.12-slim base images, Docker Compose for multi-container orchestration, 10 to 50 MB overhead per container.
- Local Model Inference. Ollama and llama.cpp: 7B Q4 model requires 4 to 5 GB VRAM/RAM, 8 GB system minimum. 13B requires ~8 GB weights, 16 GB minimum. 70B requires 38 to 45 GB Q4, 64 GB minimum. Context window impact: 7B Q4 at ~5 GB for 2K context, 10 to 12 GB at 32K. CPU inference benchmarks: 7 to 8 tokens/second on Ryzen 3700X, 2 to 5 tokens/second on typical shared VPS. GPU inference: 40 to 80 tokens/second on RTX 4090.
- Security References. FIA (Futures Industry Association): best practices for algorithmic trading including position limits, daily loss limits, kill switches, stale data detection, and hard price limits. CFTC consumer advisory: “AI technology can’t predict the future or sudden market changes,” warning about fraudsters exploiting AI interest. GitHub automated scanning for exposed API keys. OpenAI auto-revocation of keys found in public repositories.
- Freqtrade. Open-source trading framework: SQLite for all trade state persistence, position tracking, and stop-loss reinitialization on restart. Reference implementation for atomic state management in trading bots.
Editorial Note
This article covers the infrastructure requirements for running LLM-powered autonomous trading agents on virtual private servers: compute sizing, process management, broker API connections, error recovery, security, and cost analysis. It does not constitute financial advice, trading strategy recommendations, or endorsement of any specific agent framework, LLM provider, broker, or VPS provider.
The honest assessment section of this article reflects the current state of evidence as of March 2026. No independently verified, long-term track record exists for any LLM-based trading agent generating consistent profits in live markets. The StockBench and Alpha Arena results cited are the most rigorous publicly available evaluations. Individual claims of profitability from blog posts, social media, and commercial product marketing should be evaluated with extreme skepticism, particularly when the claimant sells subscriptions, courses, or software.
Hallucination rates cited (30 to 50% on certain benchmarks) are from OpenAI’s own evaluation of their o3 and o4-mini models. Hallucination frequency varies by model, prompt design, and task type. Trading-specific hallucination rates have not been independently measured. The recommendation to verify all LLM outputs against actual data before acting on them applies regardless of which model or provider is used.
VPS and LLM API pricing is current as of Q1 2026. Hetzner pricing excludes VAT. All prices are subject to change. The Hetzner cost advantage (3 to 7x versus competitors) reflects current pricing and may not persist.
The CFTC consumer advisory on AI trading claims is publicly available and applies to US-based traders. Regulatory requirements vary by jurisdiction. Using an LLM to generate trading decisions does not change a trader’s regulatory obligations. Traders managing other people’s money should consult legal counsel regarding investment advisor registration requirements regardless of whether AI is involved.
This article explicitly recommends starting with paper trading accounts and treating autonomous trading agents as decision support tools rather than fully autonomous systems. This recommendation reflects both the current evidence on agent profitability and the risk profile of connecting any autonomous system to a live trading account. The infrastructure is ready. The agents are not proven. Invest in risk controls before investing in compute.



